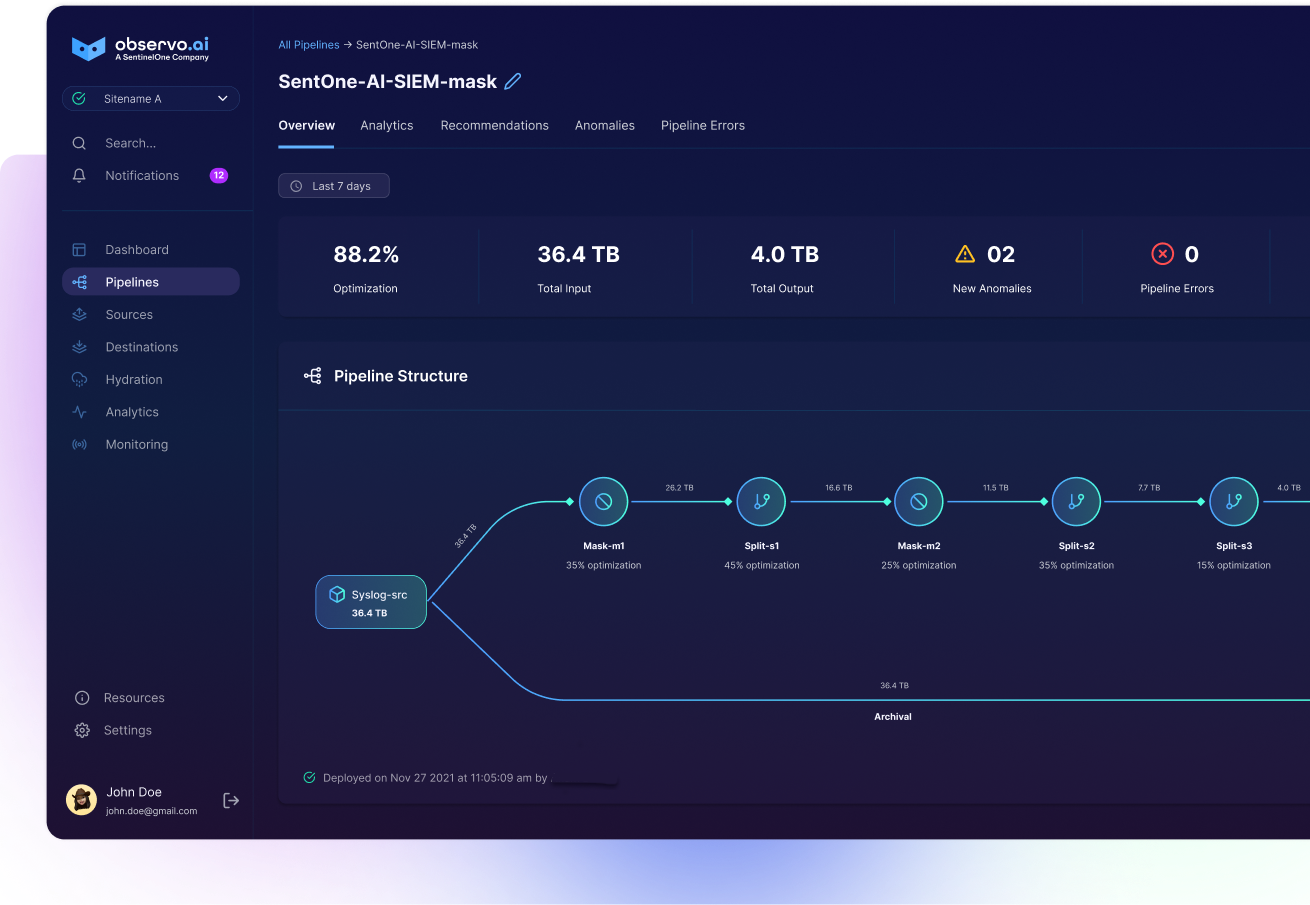
Taming Telemetry Data Sprawl: How ML Reduces Data 2X Better

Security and DevOps teams are drowning in data. Fueled by the explosion of cloud-native architectures, microservices, and accelerated software development cycles driven by AI, telemetry volumes are growing faster than ever. For most organizations, security and observability data is now doubling every 2–3 years.
At the same time, most of the tools used to analyze that data—SIEMs, log analytics platforms, and cloud-native observability tools—charge based on ingestion volume. This creates a dangerous paradox: the more data you generate to protect and monitor your environment, the more expensive it becomes to do so.
Static Pipelines Can’t Keep Up
Traditional static, rules-based data pipelines, built on handcrafted filters, were never designed to handle this scale. At best, a skilled engineer can create rules to filter out known low-value events or drop noisy logs. But these pipelines:
- Rely heavily on tribal knowledge of every log source and schema
- Require constant maintenance as formats change and new tools are adopted
- Struggle to adapt to dynamic environments where telemetry patterns shift constantly
- Fail to keep pace with evolving security threats, which change faster than static rules can be updated
In the hands of an expert, rules-based pipelines can reduce data volumes by 30–35%. But few teams have that level of expertise available for every new log source. More often, these pipelines are set and tuned at a specific point in time—based on a snapshot of the environment—and gradually become less effective as new services are introduced, log schemas change, and threats evolve. Their static nature means they drift out of sync with the environment they were built to support, reducing their effectiveness and increasing the risk of both blind spots and wasted resources.
Machine Learning Changes the Game
Modern data pipelines that use machine learning and pattern recognition offer a fundamentally better approach. Rather than relying solely on human-authored rules, ML-powered pipelines learn from the data itself—automatically recognizing redundant patterns, irrelevant values, and unneeded fields across all types of telemetry.
Across real-world environments, pipelines with ML-based optimization achieve 70–80%+ reduction in data volume—more than 2X the reduction possible with traditional methods.
Here’s how:
Smart Summarization
In high-volume environments, many log lines are repetitive—system health checks, successful authentications, or status updates that occur continuously and offer little value when analyzed individually. Smart summarization identifies these patterns and collapses them into a single, enriched event that captures the essence of what’s happening without transmitting every redundant line.
Instead of flooding your SIEM or observability platform with thousands of nearly identical events, ML-powered summarization techniques aggregate them using specified group-by fields, preserving frequency and context in a compact structure. This makes dashboards cleaner, alerts more relevant, and queries significantly faster. This is one of the biggest ways modern ML pipelines reduce data volume without sacrificing signal—compressing repetitive noise into meaningful summaries that retain the information teams need.
Field Pruning
Even non-empty fields may be ignored by downstream tools. ML can analyze usage patterns across SIEMs and observability platforms to determine which fields are never queried or visualized. These unused fields can then be safely dropped at the pipeline level, freeing up resources and speeding up searches.
What sets ML apart here is its deep understanding of downstream data usage. Rather than relying on assumptions or anecdotal field importance, ML can observe how different fields are actually used—or not used—over time. This intelligence enables pipelines to apply precise filters that reduce or eliminate unnecessary fields entirely. The result is a leaner, more focused data stream that preserves what matters most while shedding the rest.
Automated Recommendations
A powerful benefit of ML pipelines is their ability to offer proactive suggestions. As patterns shift or new data sources are introduced, the system can recommend filters, transformations, or schema changes—continuously improving efficiency without waiting for manual intervention.
Even the most experienced engineers don’t always know what they don’t know. Traditional pipelines depend on human intuition to identify what’s relevant, which often means critical patterns get overlooked or noisy data gets passed through simply because it isn’t recognized.
ML pipelines can analyze billions of events to uncover high-frequency patterns and surface them to operators for review. With this visibility, teams can interrogate whether a recurring pattern is signal-rich or just noise. If it turns out to be noise, agentic AI features within modern pipelines can automatically create and apply filters—removing the need for manual rule writing altogether.
This human-in-the-loop model means analysts retain control, but the burden of discovery and configuration is handled by the AI. It’s a smarter, faster way to ensure your pipeline is always optimized to reduce cost and increase clarity.
Out-of-the-Box Optimizers
Pre-built optimization modules for common telemetry types—like VPC Flow Logs, container logs, or identity audit logs—can provide immediate reduction benefits. These modules include embedded intelligence tuned to known schemas and frequent noise patterns, allowing them to deliver impact from day one.
These optimizers are built on machine learning models initially trained on large, diverse datasets. That foundational training allows the models to recognize which fields and patterns typically add little analytical value across environments, enabling efficient reduction before any organization-specific data is processed.
As telemetry data specific to an organization begins to flow through the system, the ML models continue learning and refining their behavior. Over time, this leads to optimizations that are tailored to the characteristics of the organization’s infrastructure, services, and data access patterns. The result is a pipeline that continuously adapts to its operating environment.
Each model is trained independently to preserve data privacy and maintain organizational autonomy. Optimization logic is isolated by design, and customer data is neither pooled nor shared between environments. This ensures that ML-based improvements are context-aware but confined to the originating organization.
This approach supports a privacy-first architecture while allowing pipelines to become more intelligent over time. Optimization responds to the realities of each environment without relying on static assumptions or shared knowledge bases. Compared to static, rules-based systems, this method offers more flexibility and long-term relevance.
Built-In Optimizations Without the Manual Tuning
One of the key advantages of machine learning pipelines is that they can perform many of the same actions static tools attempt—but without requiring weeks of tuning or deep subject matter expertise. These capabilities come pre-configured, adapt automatically over time, and get smarter as your environment changes.
De-duplication is a prime example. ML techniques detect and eliminate redundant events that occur across services or systems. In distributed environments, it's common to see the same event logged by multiple sources. De-duplication ensures that only a single, representative instance is sent downstream, reducing unnecessary duplication that clutters dashboards and drives up ingestion volume.
Header Filtering benefits from ML's ability to identify static metadata fields—like version numbers, timestamps, or service identifiers—that rarely change and contribute little to analysis. These headers can be safely removed, minimizing payload size while retaining valuable log content.
Null Value Elimination is another automated function. Logs often include placeholders or fields that are consistently empty or irrelevant. ML can detect these patterns dynamically and exclude the unnecessary fields entirely, helping shrink transmission size without compromising insights.
What makes these features even more powerful is that they work straight out of the box and improve over time. Unlike static rules that require manual creation and ongoing adjustments, ML pipelines continuously refine their reduction techniques based on observed usage, helping teams stay ahead of data growth without lifting a finger.
ML-Powered Reduction at the Edge
One of the most impactful enhancements to telemetry reduction comes from processing at the edge. Edge collection isn’t just about gathering data close to its source—it’s about empowering that collection point to act. With ML capabilities embedded in edge collectors, organizations can apply real-time summarization, filtering, de-duplication, and schema normalization before logs ever leave the environment.
This approach delivers immediate benefits:
- Bandwidth savings: Less data transmitted over the network
- Lower egress fees: Especially critical in cloud environments
- Distributed performance: Avoids overloading centralized pipeline infrastructure
- Fleet-wide control: Configuration can be centrally managed and pushed to hundreds or thousands of edge agents
In practice, this means data from virtually any source—whether it's Kubernetes nodes, virtual machines, cloud services, network appliances, or custom applications—can be filtered and optimized locally. By eliminating low-value telemetry at the point of origin, only the most relevant, enriched data is routed downstream for analysis, reducing both cost and complexity.
Edge collection also improves reliability and resilience. If a connection to the central platform is temporarily unavailable, data can be buffered locally and transmitted later, ensuring no loss of fidelity while still enforcing volume and performance controls.
Edge collection also improves reliability and resilience. If a connection to the central platform is temporarily unavailable, data can be buffered locally and transmitted later, ensuring no loss of fidelity while still enforcing volume and performance controls.
The Infrastructure Cost Advantage
The cost savings from reducing ingestion volume aren’t limited to licensing fees. Infrastructure costs can be just as significant—often exceeding the cost of the analytics software itself.
With leaner data streams, organizations benefit from:
- Smaller index sizes, which result in faster query times and more responsive dashboards
- Lower compute usage, especially in analytics environments that require parsing, enrichment, and correlation
- Significantly reduced storage requirements, since less data means fewer retention and archiving costs
- Reduced cloud egress costs, especially when logs are sent across regions or between cloud providers
Critically, none of these tradeoffs require sacrificing fidelity. Many intelligent pipelines now include the ability to store full-fidelity logs in a searchable data lake—separate from the high-performance analytics tier—giving teams the best of both worlds: lower operational costs and long-term access to data for trend analysis or investigations.
Beyond Reduction: A Better Pipeline Experience
The benefits go well beyond volume reduction. ML-powered pipelines also simplify onboarding and management:
- New data sources can be onboarded in minutes, not weeks, with automatic schema detection and transformation.
- Pipelines evolve with your environment, adapting to new formats without manual intervention.
- Analysts can explore data through natural language or intuitive UIs—no need to master regex or query languages.
These capabilities accelerate time to value for every telemetry source you add. (We covered this in more depth in the first blog in this series, “Time to Value–Getting to ROI Faster with AI-Powered Data Pipelines.”)
Less Data = More Insight
The final, and perhaps most strategic, advantage of ML-based pipelines is their ability to power downstream intelligence. With leaner, more focused data sets, it's far easier to:
- Detect anomalies and early indicators of compromise
- Identify patterns in user or system behavior
- Perform sentiment or intent analysis across logs
We’ll explore those topics in the third post of this series. But for now, one thing is clear: smart security and DevOps leaders are turning to machine learning to tame telemetry data sprawl, reduce ingestion costs, and build pipelines that can evolve with their environment—not bottleneck it. Because in today’s world, you don’t just need less data. You need better data.
To dive deeper into how leading security teams are putting these principles into practice, download the CISO Field Guide to AI Security Data Pipelines.