Integration Spotlight: Observo AI Supercharges SOCs on Elastic

Elastic is a go-to choice for organizations that want a powerful, flexible search and analytics engine without the cost overhead of traditional SIEM platforms. With its open-source foundation and customizable architecture, the Elastic (ELK) Stack—Elasticsearch, Logstash, and Kibana—has become a cornerstone for many modern observability and security workflows.
But while Elastic offers cost-effective licensing and a robust feature set, today’s security and observability data volumes are testing the limits of what teams can manage—especially when every terabyte processed adds pressure to your infrastructure budget, not just your license line.
That’s where Observo AI comes in.
Observo’s AI-native telemetry pipelines help Elastic users reduce log volume, improve data quality, and streamline ingestion. Whether you're using Elastic Security or building custom dashboards with Kibana, our platform ensures the right data gets in—cleaned, enriched, and ready to deliver actionable insights.
Let’s explore how Observo helps you get the most out of your Elastic investment—while avoiding the performance bottlenecks, storage strain, and management overhead of legacy ingestion architectures.
Why Teams Choose Elastic—and Where It Gets Challenging
Elastic is a popular choice among security and observability teams thanks to its cost-effectiveness, scalability, and broad ecosystem of integrations. As a lower-cost alternative to traditional SIEM platforms, Elastic’s open-source foundation and decoupled architecture give teams granular control over ingestion, storage, and analysis—enabling them to scale usage without rigid licensing constraints. This is especially valuable in high-volume environments, where telemetry from cloud, endpoint, and application sources grows rapidly. Elastic also excels in fast, flexible indexing and full-text search, making it well-suited for anomaly detection, event correlation, and real-time troubleshooting at scale. Its distributed architecture supports both short-term performance needs and long-term growth. Moreover, Elastic’s open APIs and extensive integration options—ranging from Beats and Logstash to third-party tools like Fluentd—make it easy to build custom pipelines and extend functionality through community-driven plugins, all without vendor lock-in.and automation workflows.
While Elastic is often seen as a cost-effective alternative to traditional SIEMs, the true costs of scaling it for security and observability workloads can add up quickly. As telemetry volumes grow, organizations face rising expenses from cloud infrastructure, data egress, and long-term storage—sometimes exceeding the cost of commercial SIEM licenses. Managing retention policies, optimizing storage tiers, and maintaining performance add further complexity. Operational overhead is also significant: teams must juggle Beats agents, Logstash pipelines, custom parsers, and schema mapping, all of which demand ongoing engineering effort. What begins as a flexible, open-source deployment can evolve into a sprawling system that's costly to operate and challenging to maintain.
Replacing Logstash and Beats with Observo

Many Elastic users rely on Logstash and Beats for ingestion and transformation—but these tools can quickly become complex to scale and maintain. Logstash in particular is notoriously inefficient, often consuming significant compute resources just to handle basic parsing and routing tasks. That’s where Observo AI offers a modern, more scalable alternative.
Observo Pipeline: A Smarter, Scalable Ingestion Layer
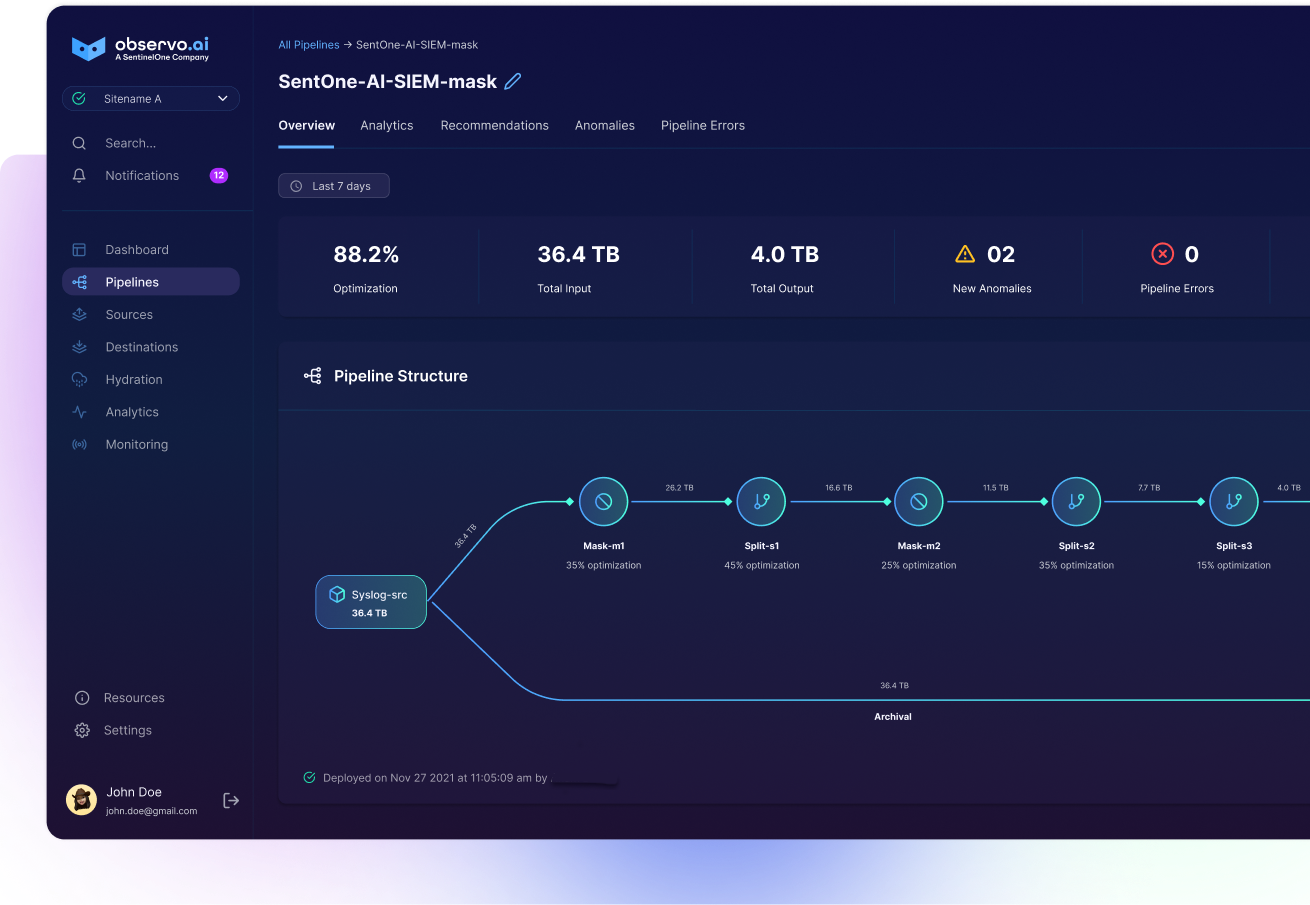
Our AI-native pipeline product handles the same core responsibilities as Logstash—but with far more power, scalability, and ease of use. Designed for modern security and observability needs, Observo AI eliminates the manual effort and operational overhead that traditional tools require, while delivering advanced enrichment, schema alignment, and high-impact data reduction right out of the box.
Observo AI can ingest and normalize logs from virtually any source, including cloud infrastructure, endpoint tools, firewalls, and custom applications—without requiring hand-built parsers or brittle ingestion rules.
It applies both traditional regex and AI-generated Grok patterns to structure unparsed logs automatically. This makes onboarding new sources dramatically faster, even for unstructured or proprietary formats.
Our pipeline enriches data in motion using threat intelligence feeds, geo-IP resolution, identity lookups, and other metadata sources—so analysts have richer context without adding processing burden to downstream tools.
It also filters low-value or redundant logs before they ever hit your index. This reduces ingestion volume, improves performance, and lowers the infrastructure costs associated with storing and querying non-actionable data.
Finally, Observo AI translates data to ECS (Elastic Common Schema)—enabling seamless dashboarding and search in Kibana without the need for constant mapping adjustments.
The result? Cleaner, leaner data that’s easier to search, easier to act on, and far less expensive to store.
Observo Edge Collector: A Modern Alternative to Beats
Instead of deploying and managing dozens—or even hundreds—of Beats agents across environments, Elastic users can turn to the Observo Edge Collector. This lightweight, centralized telemetry collector simplifies data collection across your entire infrastructure while offering built-in intelligence for filtering, enrichment, and routing. Designed for efficiency at the source, the Edge Collector reduces overhead and delivers cleaner, more actionable data to Elastic and other destinations.
The Edge Collector supports both agent-based and agentless deployment models, giving teams the flexibility to collect telemetry in the way that best suits their environment—whether it’s running in Kubernetes, virtual machines, or physical servers.
It collects logs at the edge from a wide variety of sources, including containers, cloud platforms, and on-prem infrastructure. This helps eliminate blind spots and ensures consistent visibility across distributed systems.
Data is filtered and enriched at the time of collection, reducing volume before transmission and adding context before it reaches the pipeline. This helps cut costs and improves the quality of insights from the very beginning.
Finally, the Edge Collector can securely push data to multiple destinations in parallel—including Elastic—enabling multi-platform observability or backup to a data lake, without having to duplicate collection efforts.
This reduces the operational burden of managing a sprawling agent footprint while giving you finer control over what data gets forwarded and how it’s shaped.
Route, Rehydrate, and Search with Observo Query

One of Elastic’s biggest strengths is its powerful search and visualization capabilities—but only if the data you need is readily available. Ingesting and retaining full-fidelity data in hot storage can quickly become cost-prohibitive, especially as log volumes grow. With Observo Query, you no longer have to choose between cost and visibility. Our query engine gives you the flexibility to tier your data intelligently—keeping what you need hot, and archiving the rest without losing access.
Route high-value, high-signal data to Elastic in real time so your dashboards and alerts remain fast, relevant, and accurate—without being bogged down by noise.
Send low-priority, redundant, or compliance-only logs to affordable object storage like Amazon S3, Google Cloud Storage, or Azure Blob. This allows you to retain full-fidelity logs for audit or investigation without incurring ongoing indexing costs.
When older or archived data becomes relevant, rehydrate it back into Elastic on demand. This gives your team historical visibility when they need it—without paying to keep everything indexed 24/7.
This gives teams the best of both worlds: cost-efficient retention and instant access to full-fidelity telemetry when it matters most.
Powering Elastic Dashboards with a Compliance-Ready Data Lake
Elastic excels at powering real-time dashboards, search, and alerting. But when organizations need to retain data for years—whether for regulatory compliance, forensic investigations, or historical trend analysis—relying solely on hot storage quickly becomes cost-prohibitive. Keeping everything indexed in Elastic’s real-time tiers isn’t sustainable at scale, especially when much of the data may go untouched for months or even years. That’s where the Observo AI Data Lake adds powerful long-term value.
It stores full-fidelity logs in a compressed, enriched, and queryable format—maintaining the integrity and usefulness of the data without bloating infrastructure costs. This ensures you don’t have to sacrifice detail for affordability.
It helps teams meet compliance obligations by supporting long-term data retention aligned with regulatory mandates such as HIPAA, SOC 2, and GDPR. You can maintain audit-ready archives without compromising operational budgets.
It complements Elastic’s real-time search with long-tail access to historical data—at a fraction of the cost. With Observo AI, you get the best of both worlds: high-speed, real-time visibility where it matters most, and deep, cost-effective retention where it matters later.
You can build hybrid architectures that streamline dashboards in Elastic, while keeping long-term data in a form that’s easily queryable and audit-friendly.
Making Elastic Better—One AI Pipeline at a Time
Observo AI helps Elastic users unlock greater value from their telemetry data—whether they're optimizing for cost, performance, or operational clarity. By applying intelligent data filtering, enrichment, and routing upstream of Elasticsearch, Observo AI ensures that only the most relevant, well-structured logs make it into your environment. The result: reduced overhead, faster insights, and a more scalable, sustainable Elastic deployment.
Observo AI reduces ingestion volume by 80% or more by identifying and filtering out redundant, low-value, or noisy logs before they ever reach your index. This significantly cuts infrastructure costs while improving performance across your Elastic stack.
It replaces brittle, manually maintained pipelines and agents—like Logstash and Beats—with AI-driven automation. This reduces engineering overhead and eliminates the need for hand-crafted grok patterns, ingestion rules, or complex scaling strategies.
It delivers clean, ECS-compliant data directly to Elasticsearch, making it easier to search, visualize, and correlate logs across your dashboards. This saves time and improves consistency for security analysts and DevOps engineers alike.
It routes the right data to the right destinations, whether that means sending high-signal data to hot storage in Elastic or archiving compliance-only logs in affordable object storage. This tiered approach maximizes flexibility without compromising visibility.
It enables long-term compliance without performance tradeoffs, allowing organizations to meet regulatory mandates while keeping Elastic lean, fast, and responsive for day-to-day operations.
And most importantly, it gives analysts faster time to insight—helping them detect threats, investigate anomalies, and reduce false positives with context-rich data that’s already been enriched and normalized upstream.
Elastic remains a powerful engine for search and analysis. Observo AI is the modern ingestion platform that feeds it only the data that matters—clean, contextual, and ready for action.
Better Together: Elasticsearch + Observo
Whether you're scaling Elastic Security, building observability dashboards in Kibana, or managing petabytes of cloud logs, Observo AI can help you do it faster, more cost-effective, and more efficiently.
Download the CISO Field Guide to AI Security Data Pipelines to learn how modern teams are streamlining their telemetry strategies—with Elastic and beyond.