How AI-Native Data Pipelines Help Create a Security Data Lake

Security teams are generating and storing more telemetry than ever before. Logs, metrics, traces, and events come from cloud services, applications, identities, and infrastructure across many environments. Retention requirements continue to grow, yet the cost of storing all of this data in traditional hot storage can quickly exceed annual budgets. At the same time, investigations and audits rely on fast access to historical data, and any delay can slow response time or limit visibility.
This blog explains how AI-native data pipelines help organizations create a scalable and cost-efficient security data lake in their own cloud environment. The goal is to retain full fidelity data for years, keep complete ownership and governance control, and give analysts fast access to the information they need.
The Hidden Cost of Storing Data You Rarely Use
Security teams often pay premium prices to keep months or years of telemetry easily accessible even though only a small percentage is queried regularly. Hot storage is valuable for real-time detection, but it is not optimized for long-term retention. As data volume grows, teams face difficult decisions about which logs to keep, how long to retain them, and how to support both compliance and investigation needs without overspending.
There is also a hidden cost when organizations trim retention windows too aggressively. Many incidents unfold slowly, and evidence of compromise can appear months before the first observable indicator. If a breach is discovered long after the initial intrusion, investigators need visibility into historical activity. When the data exists only for short or arbitrary intervals, analysts lose the ability to reconstruct timelines, validate findings, or understand how far an attacker may have moved inside the environment. Limited retention can turn a manageable incident into a prolonged and costly investigation simply because the necessary data no longer exists.
Many organizations want a more efficient path that allows them to store everything, search it quickly, and manage retention directly within their cloud environment. This approach preserves visibility without forcing teams to choose between cost and compliance.
Why Traditional Tools Can’t Scale to Retention Needs
Traditional retention approaches were not designed for the volume, velocity, and investigative requirements of modern security operations. Hot storage is optimized for real-time detection and alerting, but it becomes increasingly expensive as data grows. Organizations often shorten retention windows or narrow the scope of what they store in order to control costs. Even when historical data remains available, frequent access can introduce additional charges, and retrieving large datasets may require egress fees or resource intensive processes.
These constraints become even more serious when a security incident is unfolding. Static retention tools do not adapt to investigative needs. If a breach is discovered outside the predefined retention window, critical evidence may no longer exist. Time is always a limiting factor during an incident, and teams cannot afford delays caused by missing data or slow retrieval processes.
Another challenge is the lack of structure in many traditional storage approaches. Logs are often collected in bulk and stored without uniform formatting or enrichment. Investigators then need specialized query languages or SIEM specific skills to interpret the information. This slows investigations, increases the likelihood of oversight, and adds friction to compliance workflows where quick and accurate disclosure is essential. Without consistent structure or easy access mechanisms, even retained data becomes difficult to use when it matters most.
How AI-Native Pipelines Make Full Fidelity Retention Affordable and Accessible
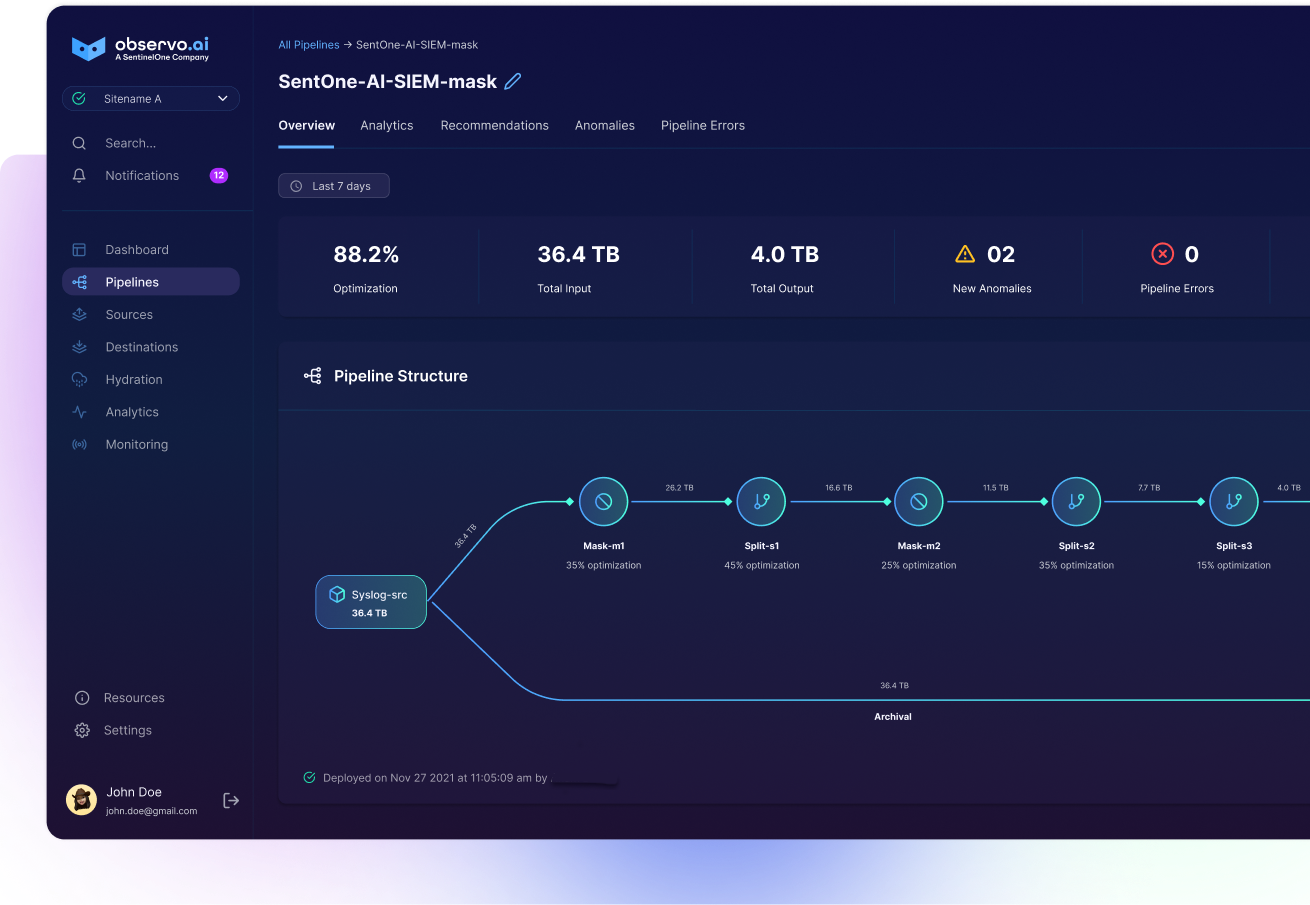
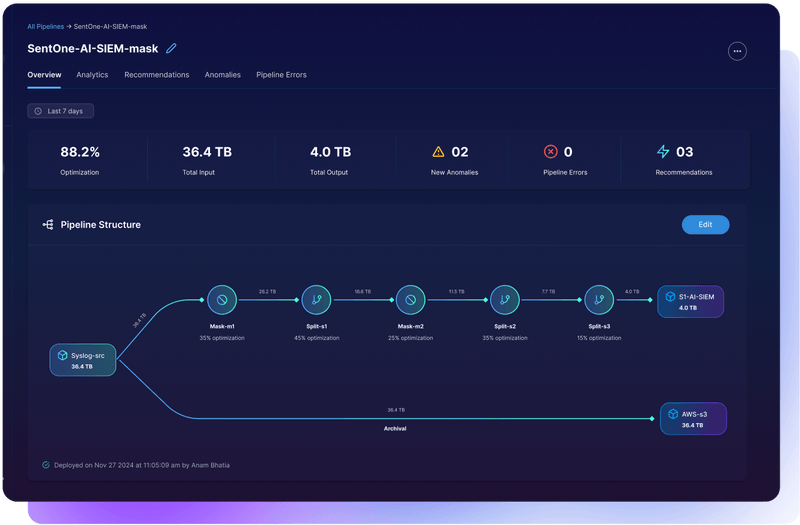
AI-native data pipelines change how organizations manage and retain security telemetry by preparing data intelligently before it reaches long-term storage. Instead of pushing raw logs directly into high cost analytics layers, AI-native pipelines standardize data into open formats such as Parquet. These formats are compact, fast to retrieve, and well suited for reintroduction into SIEM and analytics tools. The result is a consistent structure that supports long-term retention without adding operational complexity.
A key advantage of this approach is its impact on cost. Storing large volumes of security data in traditional hot storage can become unsustainable. AI-native pipelines reduce the size of the data footprint and shift retention to low cost object storage, which allows organizations to cut long-term storage costs by as much as 99 percent. This makes it possible to retain full fidelity data across far longer timelines while keeping budgets stable.
AI-native pipelines also improve how archived data is accessed and used. By organizing and enriching telemetry in motion, these pipelines create data sets that support natural language queries and intuitive search experiences. Analysts no longer need specialized query languages to explore historical information. This is especially important during investigations and audits, where fast and accurate retrieval is essential.
When deeper analysis is required, AI-native pipelines support rapid rehydration of archived data into SIEM platforms or other analytics tools. Teams can restore only the necessary subset of telemetry rather than reingesting entire data sets. This reduces processing time, avoids unnecessary cost, and ensures investigations remain focused and efficient.
AI-native pipelines provide a scalable and accessible path to long-term retention, allowing organizations to store more data, maintain full fidelity, and respond quickly to investigative or compliance needs.
What Observo AI Delivers
Observo AI gives security and DevOps teams a powerful way to retain, search, and use years of historical telemetry without the cost or operational burden of traditional storage models. At the core of the platform is the ability to build a complete security data lake directly in the customer’s own cloud environment. This ensures that organizations maintain full control over governance, access, compliance, and lifecycle management while gaining a long-term archive that is efficient, searchable, and ready for investigation at any moment.
Telemetry is transformed into optimized Parquet files that sit in low cost cloud object storage, which allows teams to extend retention windows without increasing budgets. This architecture supports compliance mandates that require long-term visibility and gives analysts the historical context they need to understand complex incidents.
Observo AI makes archived data easy to work with. Parquet formatted telemetry integrates naturally with modern query tools, including Observo Orion for natural language search and cloud native engines such as Amazon Athena. This allows analysts to retrieve insights quickly without relying on specialized query languages or SIEM specific syntax. Investigations that once required days of manual searching can often be completed in minutes.
On-demand rehydration is another key capability. When deeper analysis is required, Observo AI can restore only the necessary subset of archived data into SIEM or other analytics tools. This approach avoids the cost and complexity of reingesting entire data sets and ensures that investigations remain focused and efficient.
Organizations that adopt Observo AI experience measurable improvements across their environments. They reduce long-term storage costs by up to 99 percent and lower SIEM ingest and retention costs by up to 50 percent. They eliminate redundant copies of data across platforms, improving consistency and reducing operational overhead. Most importantly, they gain a long-term retention strategy that is searchable, governed, and built for modern SOC workflows.
Observo AI gives teams a way to unlock the full value of their historical telemetry by combining efficient storage, intuitive search, and flexible rehydration into a single, cloud native platform that customers fully control.
Real World Example: Alteryx Gains Long-Term Visibility with a Cloud-Native Security Data Lake
Alteryx faced a familiar challenge. Their cloud infrastructure was generating logs at a rapid pace, and the volume, diversity, and growth of that telemetry created operational strain. Retention costs were rising quickly, and the team needed a way to preserve full fidelity data for investigations without overloading their SIEM or limiting visibility. Data sprawl made it difficult to maintain structure across logs, and the security team wanted an approach that would scale with the business rather than constrain it.
With Observo AI, Alteryx built a security data lake inside their own cloud environment using open Parquet formats. This gave the team an efficient and cost effective foundation for long-term retention. Telemetry from many sources was normalized and enriched as it arrived, then stored as optimized Parquet files that reduced storage costs by more than 99 percent while preserving complete detail for investigative and compliance needs.
Accessing historical telemetry also became far simpler. Analysts could run natural language queries across years of archived data and surface relevant insights in minutes. Investigations that once required manual searching across fragmented systems became faster, more accurate, and far easier to manage at scale.
For Alteryx, the result is a security operation that grows with the business instead of falling behind it. They gained long-term visibility, reduced costs, and built a future ready retention strategy centered on control, simplicity, and durable access to historical telemetry.
“Observo AI and its data lake capability solve our data sprawl issue so we can focus our time, attention, energy, and love on things that are going to matter downstream."
Lucas Moody, CISO, Alteryx

Retain Everything, Keep Complete Control, Pay Less
Modern security operations depend on long-term visibility, yet traditional storage models force teams to choose between cost and coverage. AI-native data pipelines offer a way out of this tradeoff. By preparing data before it reaches storage, standardizing it into efficient Parquet formats, and enabling natural language search and rapid rehydration, organizations can store more data, keep costs low, and give analysts the historical context they need to respond with confidence.
Observo AI brings these capabilities into your environment and allows you to build a complete security data lake inside your own cloud. You retain ownership and governance of your data. You reduce long-term storage costs by up to 99 percent. You eliminate redundant copies across platforms. Most important, you gain years of searchable telemetry that supports investigations, audits, and threat hunting without slowing down your team.
Find out for yourself. Request a demo with our engineers to learn how AI-native data pipelines can help your organization create a low-cost security data lake on your own terms.