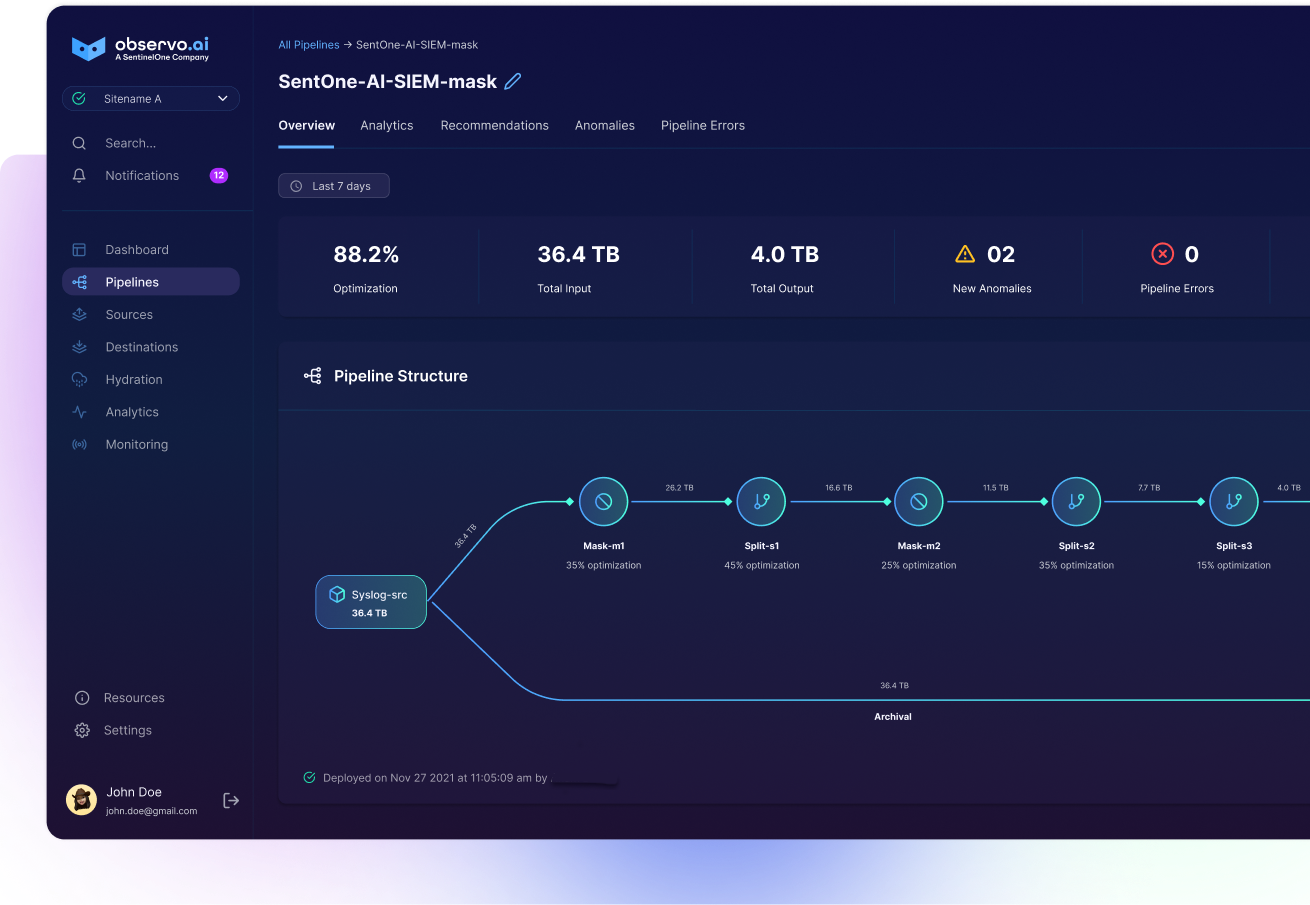
Get Better Data into Your SIEM - Data Onboarding

The Advantages of Onboarding a Wide Range of Security Data Sources
Security teams know that better visibility comes from better data. Yet most organizations are forced to make trade-offs. They either limit the number of sources they bring in to control costs, or they accept ballooning ingestion bills for data that’s 80% noise. Neither approach sets the SOC up for success.
The real value lies in being able to onboard any data source that strengthens your security posture without the penalty of ingesting noisy, low-value data that you can’t analyze. Custom application logs, SaaS audit trails, and nonstandard telemetry often contain critical signals that reveal anomalies or help correlate attacks. But in many environments, these sources are left out simply because older pipelines can’t parse or normalize them easily.
By bringing more diverse data types into the pipeline, SOCs unlock a deeper understanding of what’s happening across their environment. Security teams can correlate events across endpoints, cloud workloads, and custom applications. They can spot patterns that would otherwise be missed. And they can make decisions based on a complete picture rather than a partial one.
Modern pipelines powered by AI make this possible. They detect and map unique schemas automatically, filter out low-value events, and standardize formats so every log, no matter how complex, contributes to detection and response. The result is not just more data, but the right data that fuels faster, more accurate investigations.
Why Onboarding Data Is So Tough
If getting data into your SIEM or observability stack were easy, every team would already be analyzing dozens of sources. The reality is much messier. Each source often speaks a different “language.” Firewalls, endpoints, cloud services, and custom apps all produce logs in different schemas or formats. Aligning them into a common format is rarely straightforward.
Collectors and agents add to the complexity. Many are tied to specific destinations, creating overlap and redundancy. It’s not unusual for organizations to run multiple agents side by side just to satisfy the requirements of different tools, which drives up infrastructure costs and operational overhead.
And when teams do try to normalize these sources, the process is painfully manual. Schema mapping can take weeks of effort, requiring regex-heavy grok patterns and brittle transformation rules that break whenever a log format changes. By the time the data is finally usable, new blind spots have already opened elsewhere.
This is why many organizations limit the number of data types they ingest. But leaving those sources behind means leaving critical signals on the table.
How AI Pipelines Change the Equation
AI-native pipelines take the pain out of onboarding data by automating what used to be manual, error-prone work. Instead of relying on regex-heavy grok patterns that analysts must build and maintain, machine learning models can automatically detect structure within unformatted logs and generate parsing rules in minutes.
These pipelines don’t just parse once, they continuously learn. As new log variations appear, the AI adapts, refining its schema mapping so fields remain consistent and usable across sources. This eliminates the brittle, one-off transformations that often break when formats change.
Schema training is another critical advantage. By building a library of normalized mappings, AI pipelines can translate diverse telemetry into common, vendor-agnostic formats like CIM, ECS, or OCSF. That means teams can onboard unfamiliar data types without weeks of manual mapping, and the data is immediately ready for correlation, enrichment, and analysis downstream.
With AI doing the heavy lifting, onboarding data becomes less about wrangling formats and more about maximizing visibility. Security teams gain access to richer, more diverse telemetry without drowning in setup work or wasted ingestion.
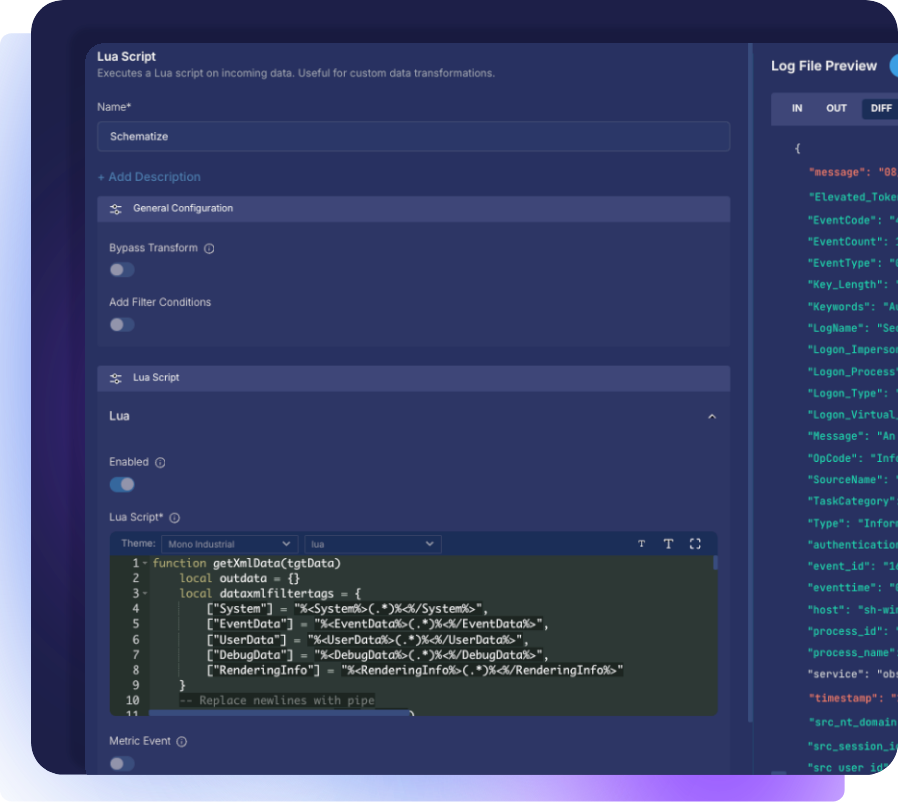
What Observo AI Delivers
Observo AI was built to make data onboarding simple, fast, and intelligent. Instead of weeks spent building regex rules or juggling multiple collectors, teams can use AI-powered pipelines that handle parsing, schema translation, and filtering automatically.
Our Grok-pattern engine detects and maps new schemas in minutes even for complex, unstructured logs like custom application data. This makes it possible to bring in sources that were previously left out, without adding cost or complexity.
Once onboarded, data is standardized instantly into vendor-agnostic formats, ensuring compatibility with any downstream tool. That means your firewall logs, cloud telemetry, SaaS audit trails, and custom app data all flow in consistently, ready to be searched, enriched, and correlated.
By cutting more than 80% of low-value telemetry at the source, Observo also makes room for new signals within existing ingest budgets. Teams can unify their data collection by replacing legacy collectors and forwarders and still process at petabyte scale with no performance lag.
The result is full visibility without the usual trade-offs. Observo AI enables organizations to expand their data sources, eliminate blind spots, and improve detection accuracy while reducing infrastructure and ingestion costs by more than 50%.
Real-World Example: Informatica Onboards 70+ Schemas in Days
Informatica, a global leader in SaaS data management, faced one of the toughest onboarding challenges imaginable. Their applications generated logs across more than 70 custom schemas each with its own format and unique quirks. Normalizing and parsing that telemetry before Observo was a slow, manual effort that consumed valuable engineering time and still left critical signals out of their analytics systems.
When they deployed Observo AI, the difference was immediate. Instead of relying on regex-heavy rules or weeks of schema mapping, machine learning models automatically parsed logs from dozens of formats. Where native parsing wasn’t available, the team used AI-assisted schema training and lightweight lua scripting to quickly define transformations.
Within just a few days, Informatica had successfully onboarded all 70+ schemas, something that previously would have taken months of effort. The result was broader visibility across their entire environment and the ability to analyze complex application logs that had never been usable before.
“We onboarded over 70 unique application schemas in days and the platform has been running smoothly ever since.”
– Kirti Parida, DevOps Architect, Informatica
By removing the barriers to schema onboarding, Informatica expanded visibility, improved detection accuracy, and eliminated blind spots without adding to ingestion costs or infrastructure overhead.
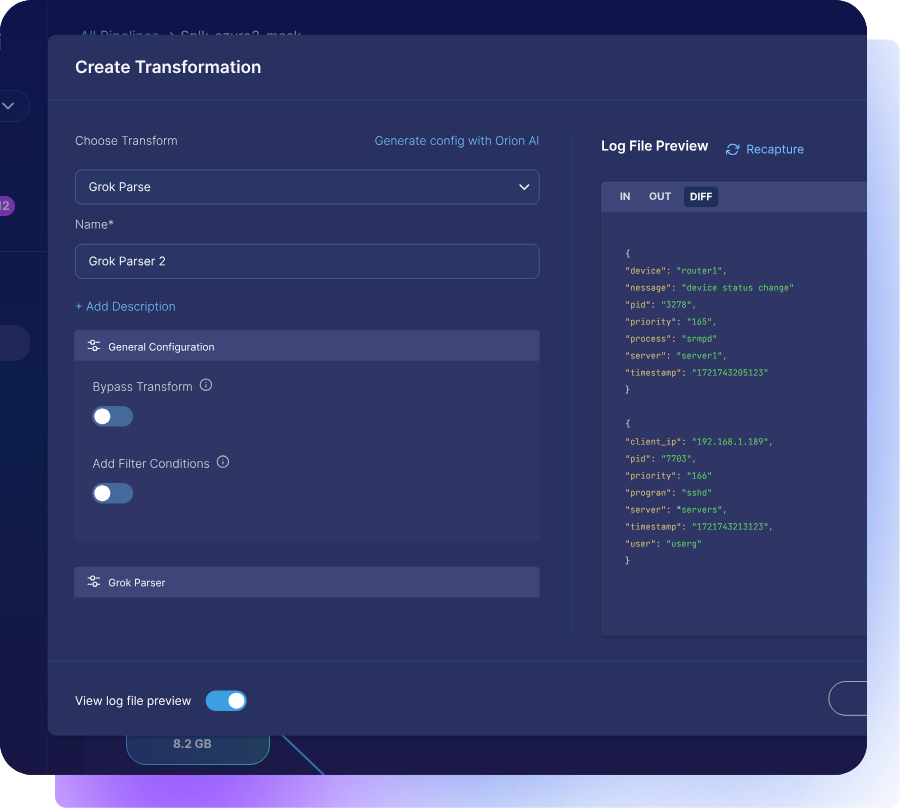
Onboard New Data Sources with Ease
Complex schema translations shouldn’t dictate what data you analyze and what you hope won’t lead to the next incident if you don’t send it to your SIEM.
AI and machine learning make it possible to bring in these difficult data types quickly. They translate them into usable formats and send them to any SIEM or downstream tool. With Observo’s AI-native pipelines, you can do this with speed and confidence while expanding visibility and keeping costs under control.
Find out for yourself - request a demo with our engineers and experience how Observo AI helps you onboard any data source and make smarter security decisions.